AskMob was a social media app that I created and managed over the course of 3-4 years. This product had nearly 100k downloads over the span of its life! Even though this project is not active on the marketplace still; I am very proud of what I accomplished with this. The mobile apps were developed in their native languages, the server code was all java based and managed in docker containers. The product was hosted in the google cloud and was engineered to scale across data center regions.
It all started back in 2015 when myself and my old business partner decided to get together and create this product which at the time, all we had was an idea, so I started down the long road of building out all solutions from scratch. This took me roughly 1 and a half years to get everything built which is mostly due to the fact that I was working a full-time job and building this out at the same time. When we went live with the project, I had written so much code that if this took off, I had a plan to print every single line of code from “Version 1” and line the walls of a conference room in what would essentially have to be “bible font”.
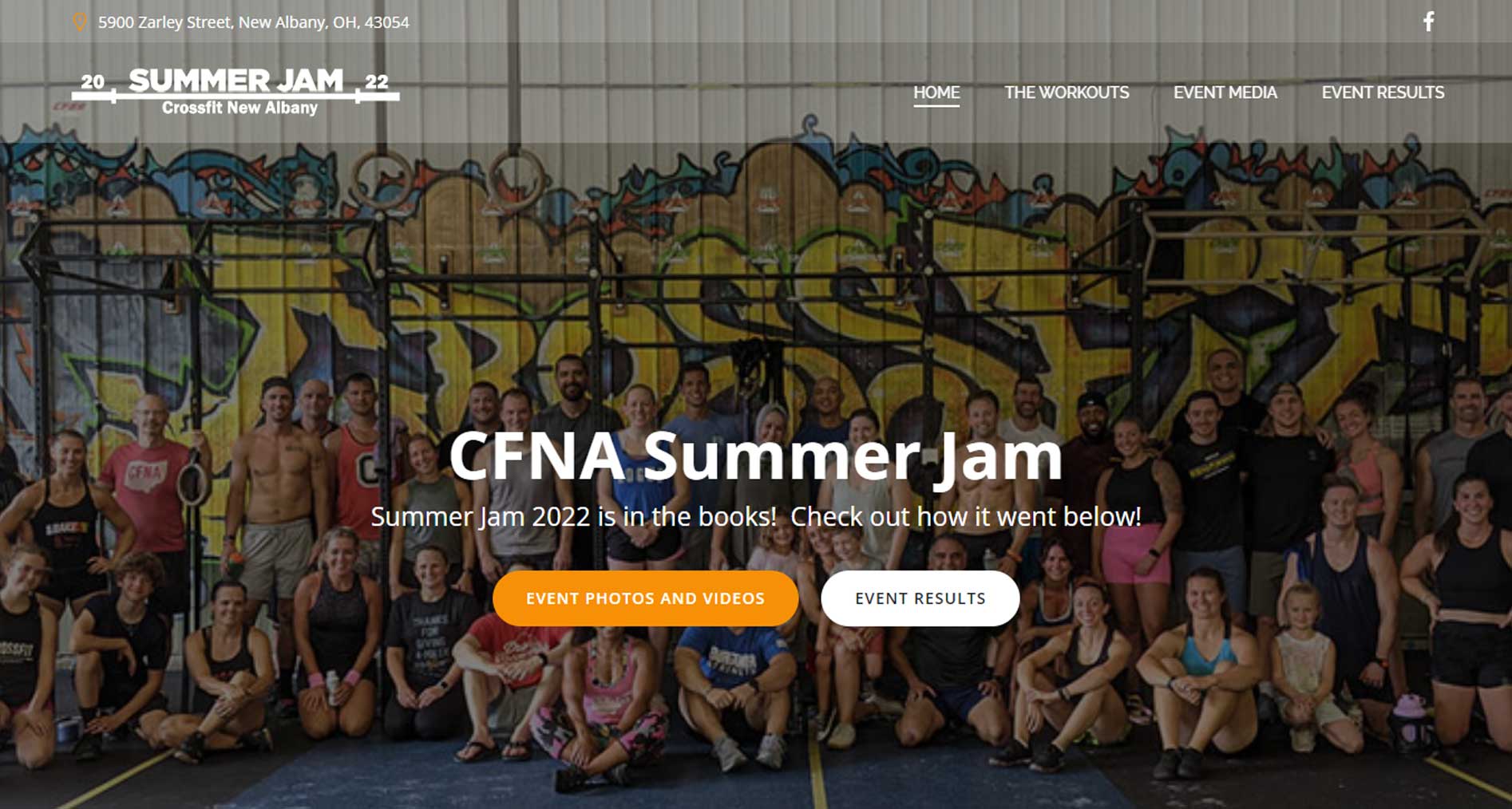
Version 1 of this application ended up becoming an amazing product IMO! The function of the service was engineered for people to ask/answer questions in your local area and to connect with people. This service was geo-location driven so results were delivered/ordered based on many factors but location to you was a huge factor.
The technology behind this product was even more impressive because I engineered this to scale from a handful of users to millions of users overnight if it were to grow that big. The focus on this project will be how this product was built and engineered to manage infinite demand from any region in the world.
The Technology Stack and Products Created:
- Android Native App: Java/Android
- iOS App: Objective-C/iOS
- App Service API: Java API/Docker
- App Management Site: Java MVC/Docker
- Google Cloud: Docker, Kubernetes, mySQL, NO SQL
Mobile App Overview
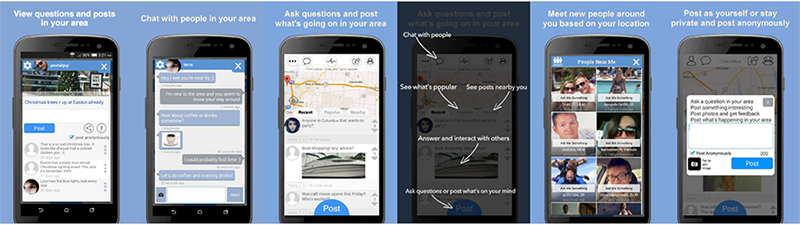
I created 2 separate versions of the same app for the Android and Apple marketplaces respectively. I opted not to go with a common code base because at the time anything that was out there was clunky and had limitations. I set off to create each app in their native languages which took a long long long time not just because each code base was so fundamentally different, but because I also had to ensure that the API Endpoints work exactly the same for each code base. That means encryption, encoding/decoding, business logic against end points, etc. all works exactly the same in different code bases/technologies.
However these apps did diverge on concepts when it involved things such as push notifications, analytics, etc. Each app had to incorporate the originating companies services to be able to support all features required for the application requirements. If I were to re-do these applications today, I would make a single app and abstract away all of the resources below however at the time I needed a fluid/non-clunky user experience which is why I opted to develop all of this technology natively.
The application functionality was relatively basic but also followed the exact same user experience between tech stacks. I ended up mapping out the full user experience below that each application would follow. The picture below illustrates how the application would work in regards to the user experience. Keep in mind that a simple box below represented an application module, for example the module “Messenger” was not a module which was developed over the course of a weekend. It involved extensive UI development, server development and integration with services that the android/apple platforms manage such as push notifications.

A Design to Scale – Overview
The app functionality had some depth to it and was engineered well enough to make a viable product. To me the most impressive and fun part to build out was the technology and how it was engineered to scale. To start, this was all engineered in the Google cloud and ended up working extremely well once implemented.
To start, I could not let this run on top of an RDBMS for many reasons however I did consider this to be a good solution for storing data at what I viewed as stale/resting data. I decided to use a NO SQL DB as the primary data set that the API Services would interact with. This NO SQL Solution was setup regionally so the data sets held in memory in the US was different than the data sets held in memory in the Asia Pacific regions which ultimately was all based on demand in the regions they represented.
The API Hosting tier was setup to use Kubernetes to scale the API Services which were developed and deployed to docker instances. The one thing I did do was separate the product management code from the Mobile App Service code. The Mobile App Service code was the only thing that needed to scale, the product management code was a single instance of Java MVP App which was used to manage rules, view the status of the product, and the over management of this product.
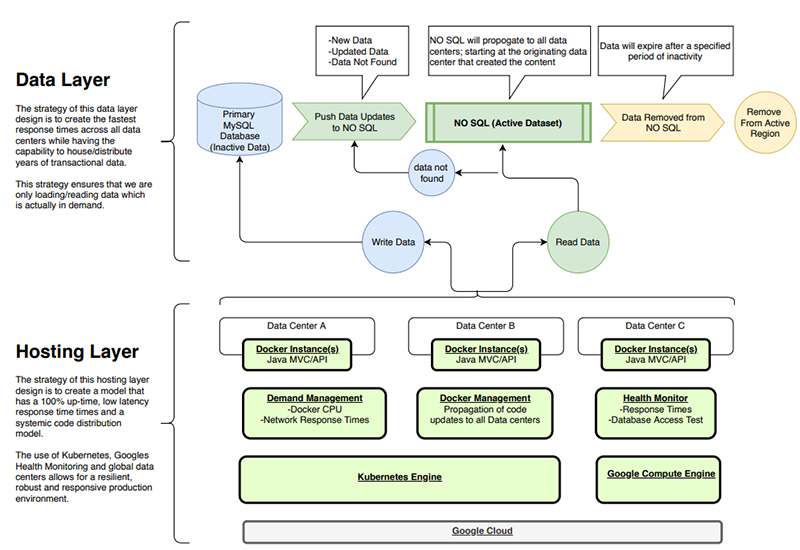
Data Layer Scaling
Lets get into some of the details around the scaling of the data layer because this is the part that I found worked almost amazingly smooth as Kubernetes does managing docker instances. Since the data that the mobile applications relied upon was immutable, I was able to easily use the NO SQL datasets as the primary mechanism for data access. The NO SQL dataset would only house data that is in demand for X-Amount of time. X being a factor that I could change regionally based on demand. The API Service would handle each request, if the data was not in the NO SQL dataset or it was new data being introduced, then it would talk to the RDBMS Db to request or insert the data set. The API Service would also add this new dataset in question to the NO SQL Dataset and then move on with its life.
The great part about this model is that the NO SQL Dataset would automatically expire the stale data over time as it expired due to inactivity. This allowed the NO SQL instance to essentially scale up/down based on demand and I was able to easily control costs based on the frequency of use and how long I allowed the stale data to just sit there.
The one flaw in this model was the Singular mySQL Database. To start I chose mySQL due to cost savings and the fact that it was serving an extremely simple function. I knew if this thing grew bigger then I would have to learn to to scale the mySQL Database as well OR change to a new solution. However based on how well this model was working, I would not have to even approach that subject until we have millions (plural) of users at which time I would be happy to solve that problem.
API Service Layer – More than just Scaling
I am not going to get too deep into Kubernetes because there are thousands of articles out there on this and how it is the most amazing product on the face of the planet. I can confirm that it is an amazing product and it helped me to sleep well at night as it solved more than just my scaling needs.
I was able to easily scale my docker instances up/down easily regionally with this tool as demand would rise and shrink which that part was easy. It helped me to effectively manage my API Service layer versioning, health and gave me incredible feedback on problems.
The 1 of the 2 aspects that I really loved about managing my docker instances using Kubernetes in the Google Cloud was how I could version my docker images and then tell Kubernetes to slowly re-distribute the new instances. This means that I could easily release new versions of my software without having any downtime. Inversely if I needed to rollback a release, I could easily do this with ease.
The 2nd of the 2 aspects that I loved about managing my docker instances using Kubernetes was the Health aspects. I created endpoints in my API services that would return health statistics on that specific docker instance. If that docker instance became unhealthy then it would automatically be destroyed and re-created. This helped me on a few occasions when I wrote some bad code which was not managing my IOC properly and ultimately dropping my database connections. This kept my services alive until I could release new code that properly managed this aspect. Having assurances like that really helped me sleep well at night knowing that they system was so self-sustaining baring a few meteor strikes hitting isolated data centers at the exact same time!
Project Overview and Retrospective
This took away from a large part of my life developing this entire system from scratch by myself but I am so happy that I did it for the experience. This product had just under 100k downloads, was published by a lot of websites and helped me better understand how to develop systems to better scale. This understanding is far more that understanding Kubernetes and Docker, but how to develop code, services, apps, etc. to all work as one collective/singular system. If I were to do this all over again now, I certainly would not follow this path but the new version of this would definitely take away lessons learned from this exercise.